2年上百亿,中国大模型,闯入一个“扫地僧”
自从2022年11月30日那场名为“ChatGPT”的飓风席卷以来,近2年时间内,我们看到了一场人工智能时代的“淘金热”。
重金押注的大厂、盆满钵满的上游、跃跃欲试的初创……
“谁会成为中国的OpenAI”?
今天,我们围绕第二名讲一个故事。
一、最接近OpenAI
“未来世界第二的大模型公司应该是一家中国企业。”
争第二,这不是一个富有吸引力的故事该有的开头,却意外引人思考,也是闫俊杰说话的一贯风格——客观、直白、坦诚到出人意料。
类似的表达还有很多:
“做大模型,快就是好,好就是快。”
“在探索前沿技术的道路上,最好的公司实际上是殊途同归的。”
“实事求是地讲,跟国外先进公司比起来,国内现阶段所做的都是弥补差距。”
ChatGPT发布以来的不到两年里,中国的大模型创业圈热闹到甚至有些喧嚣,与此形成鲜明对比的,是很长一段时间里“沉默”的闫俊杰。
当ChatGPT还没发布,其它中国公司都还没出来,前东家眼看要上市,闫俊杰却跳出来要做通用人工智能的时候,他是沉默的;
当2023年下半年,投注公司80%可用资源去“死磕”MoE(混合专家系统)模型却连续失败两次,被业内审视的时候,他是沉默的;
当公司MiniMax旗下的星野、Talkie等自有产品月活数千万,在中国甚至海外市场遥遥领先,公司估值上百亿时,他依然是沉默的。
有了解MiniMax的人曾经形容,闫俊杰就像是“扫地僧”,不显山不露水,但手上都是真功夫。
也正因此,当这样一个人开始逐渐出现在公众视野中的时候,难免被问及是发生了怎样的心态转变。
闫俊杰仍然思路清晰:“为了高效地吸引人才”,随后又提到,“最近在办一场活动,也让合作伙伴和用户更加了解我们在做的事情。”
这场活动指的是昨天刚刚结束的MiniMax Link伙伴日,任何一位对AI有所关心的人都会意识到,闫俊杰所说的沟通有多么必要。
即便当前每天有数百万的年轻人在“星野”与各种智能体对话,每轮平均对话时长达到了惊人的100分钟,即便MiniMax每天与世界发生30亿次交互,是中国最接近OpenAI的公司,即便其开放平台目前已服务超 30000家企业用户和开发者,自有产品累计用户超过6000万,看完这场大会,我们仍会觉得对MiniMax缺乏了一些想象力。
举个简单的例子,30亿次交互什么概念?
这意味着MiniMax的模型每天要处理超过3万亿的文本Token,相当于3000个人一辈子处理的文本量,更不用说这其中还包括每天生成2000万张图、7万小时的语音。
这个数据处理量放在国内,大概率是所有的头部公司里最高甚至可以说是断层高的,对比近期其他两家大厂最近披露的5千到1万亿Token处理量,多出2-3倍的MiniMax可谓遥遥领先。
这不禁让我们想起2023年的那个春节,ChatGPT“新鲜出炉”,通用人工智能(AGI)概念大热,一众创业者摩拳擦掌,全中国的风险投资机构都在满世界寻找“谁是中国的ChatGPT”时,却发现MiniMax和它的Glow就已经在那儿了。
一位OpenAI的工程师曾说,他判断一位人工智能创业者到底有没有真正的AGI信仰,就看这个人是在ChatGPT发布之前创业还是在这之后。
MiniMax在ChatGPT出来之前成立,而大部分公司在这之后,这本身就是核心的区别。
只不过,随着ChatGPT的发布带来“世界线收束”,闫俊杰终于不再需要跟每个人解释他的理想了——
Intelligence with everyone,用最好的技术服务每一个人。
二、有一天,“AI不再是AI”
闫俊杰对通用人工智能的信仰从何而来?
这是一个复杂的命题,但跟他本人聊完,答案又出乎意料的简单。
回顾闫俊杰的履历,先是在中科院和清华大学研究计算机视觉,又从实习生一路做到商汤副总裁、研究院副院长和智慧城市事业群CTO,接着自己创业。
做学术的时候论文在Google Scholar上有接近3万次引用,做企业如今估值也已经上百亿(25亿美元)他好像总能胜任各种职能。
但在他自己看来,这是“被迫”的:
“过去我能做很多工作,可能跟我的成长经历有关,我出生在河南一个小县城,很多东西周围没有人教,只能靠自己,这就形成了自己领悟事情的能力。我也不想这样,我是被迫变成这样。”
也正因如此,一旦想清楚自己要做什么,即便没做过,闫俊杰也能快速找到一些底层逻辑。
对通用人工智能的信仰也是如此。
事实上,闫俊杰曾提到:“我有好几次都是想去当老师的。博士毕业后就拿了教职准备去当老师,甚至前几年刚从商汤离开的时候本来也准备去当老师的。”
当然,这些最终都没有发生。
因为闫俊杰意识到:“不能再把人工智能单纯看成科学了,它更是一个技术,而且不是在遥远的未来,就在很近的地方。”
当这种感觉一直在脑海中盘旋,并且越来越强烈,引爆,只需要一个触点。
“有一天,我外公告诉我他想写一本书,讲自己几十年的经历。但他没有办法,因为这需要非常好的语言组织能力,还至少要会打字。
那个时候,我认为只有人工智能可以帮他实现这件事。”

图注:小时候的闫俊杰和外公
可是,当时的人工智能技术非常依赖根据特殊的需求来定制模型,只能解决特定的问题,比如人脸识别,语音识别等。
如果一个有价值的技术只能发挥局限的价值,那一定是方法不对,或者说路线不对。
闫俊杰开始意识到,想解决这个问题,唯一办法就是把人工智能变得更加通用,变成普通人生活中的一部分。
“当时整个人工智能行业遇到困境,我一直在思考什么样的技术进步可以给社会带来足够高的反馈,想到了电动车、移动互联网,结论几乎只有一个——要做出足够产品化、能服务大众的人工智能技术和产品,而不是服务少数大客户的项目。”
从做人工智能转向做通用人工智能,闫俊杰决定入局。
至此,MiniMax成为国内第一个说AI to C的公司,彼时,大模型这个词甚至还没有风靡,用简化的语言描述可交互的智能体,他们一度被当成是在做数字人。
现在,越来越多人开始畅想通用人工智能真正实现的那一天,闫俊杰对这幅图景也有一个自己的定义——
“就像我们今天谈到抖音,你不会觉得它是一个基于推荐系统的内容分发软件,你只会觉得抖音就是抖音。
什么时候大家认为AI不是AI,那一天大概就到来了。”
三、“这是唯一的路,做不出来就完了”
今年1月,MiniMax推出了自己的abab6.5模型,是国内第一个推出MoE(混合专家系统)架构大模型的。
形容“死磕”MoE模型,坚持做底层研发的那6个月,闫俊杰提到了“痛苦”两个字。
很多人会问他:为什么?有必要吗?值得吗?
毕竟在过去一年里,同行大多在迭代Dense(稠密)模型,这种模型参数固定,在推理过程中不需要进行复杂的路由选择或专家激活操作,有助于提高计算效率,况且结构相对简单,易于实现和部署,开发者能轻松地将其应用到项目中。
但它也有一个对国内企业而言致命的缺点——资源消耗大。
随着模型规模的增大,Dense模型所需的计算资源和存储资源也会显著增加。
换句话说,在国内缺算力的大环境下,基于Dense不可能做出一个万亿模型,相当于直接把自己的天花板封死了。
但MoE模型不同,同样的智能水平,MoE模型可以用更少的计算量和内存需求来实现。这得益于MoE模型在应用中并非要完全激活所有专家网络,而只需要激活部分专家网络就可以解决相关问题,很好避免了Dense模型会出现的“杀鸡用牛刀”的尴尬局面。
因此,拿出全公司80%的可用资源,耗时6个月,哪怕失败两次也绝对不能放弃,这不是闫俊杰在豪赌,而是他心里清楚:
“我们不是有两条路可以选择,而是说为了实现目标,这是唯一的一条路,做不出来就完了。”
当被问及中途失败两次的时候慌没慌过,闫俊杰也并不避讳,说不伤心不紧张那都是假的。
“模型训了半个月,发现一些指标离前期估测的越来越远。这就像你发了一个火箭,本来以为它可以到三万米,但它偏航了。
你开始想哪个地方错了,把问题解完之后,发现还没有回到一个好的状态,又失败了。”
每一次烧的都是钱,比钱更重要,还有时间。
但最终,随着模型成功研发出来,闫俊杰神奇地发现,过程中的挑战其实并不是MoE模型本身带来的,而是在实际操作中团队对于实验方法、网络、数据结构的探索存在不足。
伴随abab6.5的诞生,一个经过淬炼的团队也随之形成,闫俊杰明显感觉到整个研发部门经此一役后更高效、更科学,甚至士气都得到了很大的提振,面对技术攻关充满信心。
在MiniMax的企业文化里,有一条叫做不走捷径,听起来简单朴实,但这其实在对抗人性。
闫俊杰自己就说:“哪怕去年我们都还在讨论要不要走私有化,模型做出来了一卖,快钱就到手了,但这很明显是不持续的,也没有给客户创造真正的价值。”
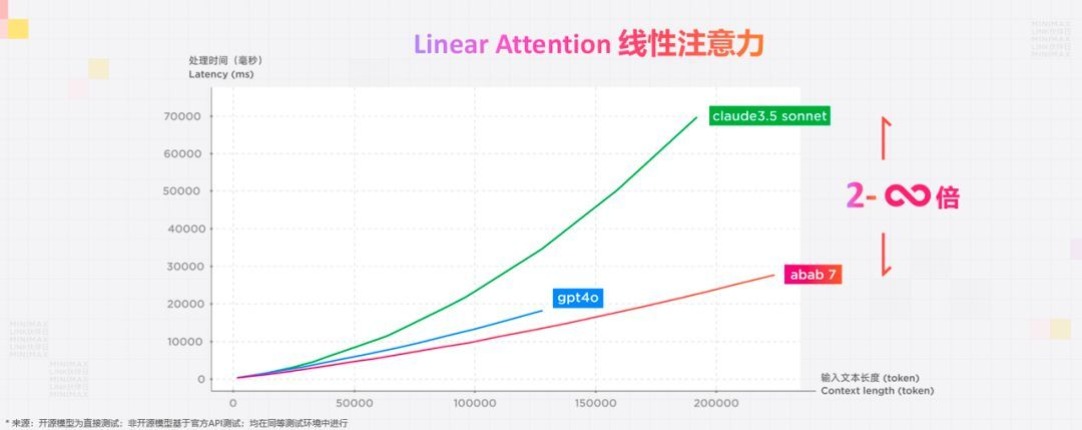
如今,更多国内大模型创业公司开始投注资源研发MoE模型,当这成为了一个新的行业共识的时候,MiniMax已经在做更进一步的探索了。就在昨天,MiniMax宣布,他们探索出了更难更好的Linear Attention与MOE相结合架构,这将使MiniMax的模型效率大幅提高。其实LinearAttention架构作为打开无限长度输入跟无线长度输出的一个关键的钥匙,早在2019年就被提出了,只是一直没有人做出来。
这个架构好到什么程度?它让MiniMax的abab7.0模型利用国内有限的算力,达到了一个真正可以比肩GPT4o的效果。
当然,MiniMax的努力远不止于此。
类比人,文字交互只是很小的一部分,多模态的内容,比如声音,图文和视频,才是信息传递的主流。
就在昨天的伙伴日上,MiniMax推出了它的第一个视频模型,并使用一个全面的“视频生成模型的评测框架”V-Bench进行了评测。
结果显示,这应该是全球目前大家能用到的最好的生成模型。
不走捷径地连续技术突破,让MiniMax在创新上一次又一次引领。
四、从Glow到今天,MiniMax不仅仅是卖技术的
说起AI在国内的热潮,这并不是第一次。
实际上,这两年热闹的大模型创业潮,被业内称为“AI 2.0”。
与之对应的“AI 1.0”,指的是2015年左右开始的那一波AI创业潮,当时诞生了商汤、旷视、云从、依图等明星创业公司,它们以CV技术(计算机视觉)为主导,大量融资,风头无两。这四家公司,是公认的“AI四小龙”。
“AI四小龙”当年也从投资人手中拿了很多钱,但最后却没有从市场上赚到多少钱。
这不是因为它们技术不好,而是商业化很难,客户主要是B端企业和G端政府,通过提供人脸识别等AI解决方案来赚钱。
这显然不是一个好的商业模式,项目非标准化、落地周期长、成本高,导致后来一提到“AI四小龙”,人们总是会想到亏损、烧钱等标签。
如今的大模型创业公司,同样要面对来自商业化的拷问。
这一点,闫俊杰也想得很实际,那就是一定要在技术快速进化的窗口关闭前,做出用户量巨大的2C产品。
“如果没有产品承接,即使你有一个技术进展,它最终也不是你的。”
说白了,一味地秀肌肉作用不大,能用它搬起砖、盖起楼、让用户住进去才是正道。
闫俊杰说到做到。
如今,MiniMax是中国大模型创业公司中做产品最早、最多,投入也最大的一家:
MiniMax如今300-400人,其中一半以上是技术团队,另有40%负责产品。他们的第一款产品Glow上线于2022年10月,之后又陆续推出了星野、海螺AI等至少4个产品,既有AI内容社区应用,也有问答等生产力应用,多个应用的日活用户已突破100万,每天与世界交互30亿次。
对于大模型创业公司,李彦宏有个经典的观点,他认为“双轮驱动”,即同时做模型和应用不是个好模式,很多人也拿这句话来考验过闫俊杰。
他实事求是:“一开始创业其实没资格想这些事,因为你既没有技术又没有产品也没有用户。前六七个月只是把最原始的模型做出来,才有了后面的产品。”
但是产品要不要做?
必须做。
这就不得不提到MiniMax的另一条企业文化:User-in-the-loop,与用户共创。
闫俊杰很清醒:“我一直不认为AGI会像一个原子弹、一个大杀器,它就是普通人每天会用的一个产品、一个服务——这也是我们最坚持的。
这也就意味着AGI也不应该是一家公司自己做出来,它要靠这家公司和它的用户一起做出来。”
实际上也不难理解,当MiniMax的愿景是让好的技术服务每一个人的时候,不去研发产品,不去接受一手的用户反馈,似乎才是荒谬的。
只是,好的产品,好的用户体验究竟从何而来?
移动互联网时代流行过一个口号,叫做“人人都是产品经理”,产品的设计和用户的需求推到至高无上的地位,大模型时代会继承这一点吗?
MiniMax也曾纠结过,产品和技术同时做,都重要,但哪个才是核心?
最终,闫俊杰在公司成立一年多时将新的四个字加入企业文化——技术驱动。
至此,尘埃落定。
背后缘由,也来自一次惨痛经历。
2022年底,MiniMax团队几乎全员感染新冠,结果最后一次发版里出现了一个bug,把用户的对话体验拉低了15%左右。
仅元旦三天,产品的日活跃用户直接掉了40%,大家焦头烂额,终于在放假最后一天找到了那个bug,非常小的一行算法,改好之后用户量很快就回来了。
这个事让闫俊杰意识到,现阶段产品价值的来源,核心还是模型性能和算法能力,不然设计再多产品特性,提升都是有限的。
而在本次伙伴日大会上,MiniMax基于MOE+Linear Attention的abab7模型家族的预热发布,更是让他们对于技术驱动的坚持再次得证。
行胜于言。
图注:MiniMax成立第一天写下的初心和蓝图
五、结语
如果我们来总结MiniMax的发展之路,这无疑是一场田忌赛马的胜利。
“在整体资源劣势的情况下,创造出局部的优势,进而有机会获得整个战役的胜利。由此,平凡人可以成就非凡事。”
在移动互联网爆发初期,人们热衷于谈论那些天才的产品设计(比如微信)和它背后的美学甚至哲学理念。
但到了大模型人工智能阶段,产品设计的逻辑变了——
在由技术驱动的底层之上,用户开始在内容上深度共创,他们的使用同时反哺着产品本身进化。
率先领悟的,率先成长。
我们都在遥望通用人工智能的曙光,MiniMax已经踏入河流。
本文转自于 正和岛标准